Développement¶
Général¶
GeoNature 1, créé en 2010, a été développé par Gil Deluermoz avec PHP/Symfony/ExtJS.
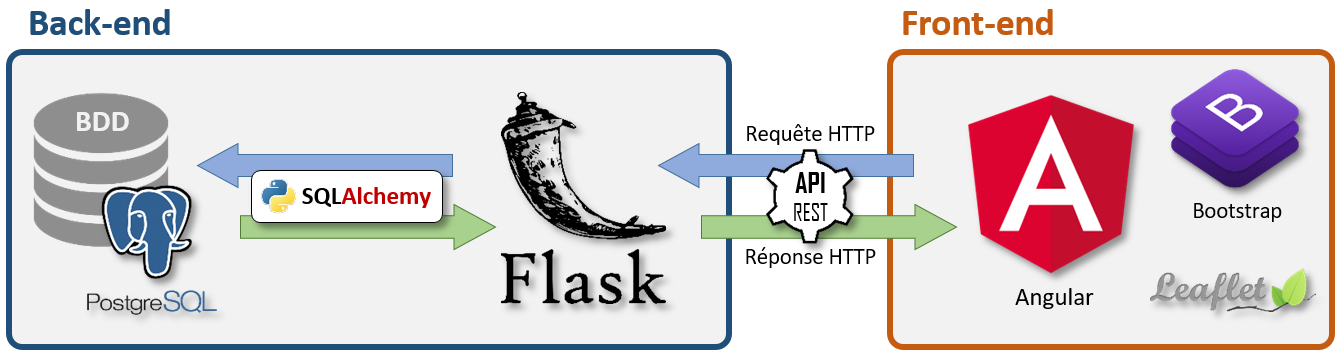
GeoNature 2 est une refonte initiée en 2017 par les parcs nationaux français en Python/Flask/Angular.
Mainteneurs actuels :
Jacques FIZE (PnEcrins)
Pierre NARCISI (Patrinat)
Vincent CAUCHOIS (Patrinat)
Élie BOUTTIER (PnEcrins)
Théo LECHEMIA (PnEcrins)
Amandine SAHL (PnCevennes)
Camille MONCHICOURT (PnEcrins)
API¶
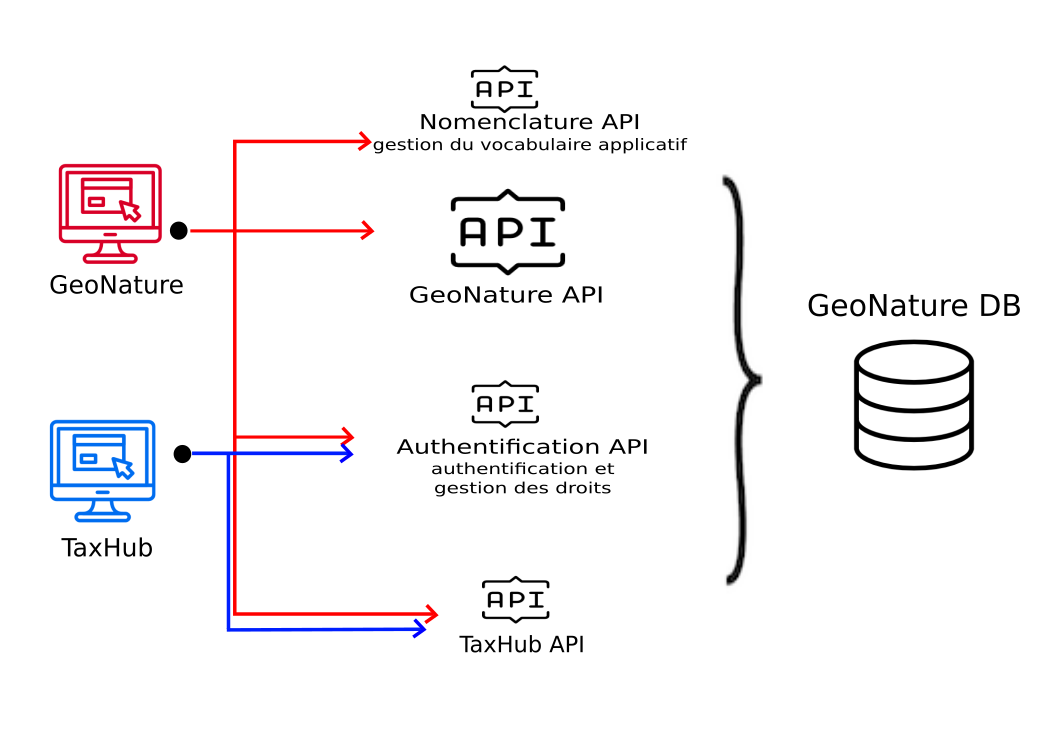
GeoNature utilise :
l’API de TaxHub (recherche taxon, règne et groupe d’un taxon…), intégrée à GeoNature depuis sa version 2.15
l’API du sous-module Nomenclatures (typologies et listes déroulantes)
l’API du sous-module d’authentification de UsersHub (login/logout, récupération du CRUVED d’un utilisateur)
l’API de GeoNature (get, post, update des données des différents modules, métadonnées, intersections géographiques, exports…)
Liste des routes¶
Vous pouvez obtenir la liste des routes de GeoNature avec la commande suivante :
geonature routes
Documentation des routes¶
Génération automatique actuellement hors-service :-(
Pratiques et règles de developpement¶
Afin de partager des règles communes de développement et faciliter l’intégration de nouveau code, veuillez lire les recommandations et bonnes pratiques recommandées pour contribuer au projet GeoNature.
Git¶
Assurez-vous d’avoir récupéré les dépendances dans les sous-modules git :
git submodule init && git submodule updateAprès un
git pull, il faut mettre à jour les sous-modules :git submodule updateNe jamais faire de commit dans la branche
mastermais dans la branchedevelopou idéalement dans une branche dédiée à la fonctionnalité (feature branch)Faire des pull requests vers la branche
developFaire des
git pullavant chaque développement et avant chaque commitLes messages des commits font référence à un ticket ou le ferment (
ref #12oufixes #23)Les messages des commits sont en anglais (dans la mesure du possible)
Privilégier les rebases afin de conserver un historique linéaire
Privilégier l’amendement (
git commit --amendougit commit --fixup) des commits existants lorsque vous portez des corrections à votre PR, en particulier pour l’application du style.
Backend¶
Une fonction ou classe doit contenir une docstring en français. Les doctrings doivent suivre le modèle NumPy/SciPy (voir https://numpydoc.readthedocs.io/en/latest/format.html et https://realpython.com/documenting-python-code/#numpyscipy-docstrings-example)
Les commentaires dans le codes doivent être en anglais (ne pas s’empêcher de mettre un commentaire en français sur une partie du code complexe !)
Utiliser blake comme formateur de texte et activer l’auto-formatage dans son éditeur de texte (Tuto pour VsCode : https://medium.com/@marcobelo/setting-up-python-black-on-visual-studio-code-5318eba4cd00)
La longueur maximale pour une ligne de code est 100 caractères. Pour VSCODE copier ces lignes le fichier
settings.json:
"python.formatting.blackArgs": [
"--line-length",
"100"
]
Privilégier la snake_case pour les variables, CamelCase pour les classes.
BDD¶
Le noms des tables est préfixé par « t_ » pour une table de contenu, de « bib_ » pour les tables de « dictionnaires » et de « cor_ » pour les tables de correspondance (relations N-N)
Les schémas du coeur de GeoNature sont préfixés de « gn_ »
Les schémas des protocoles ou modules GeoNature sont préfixés de « pr_ »
Ne rien écrire dans le schéma
public
Modèle Python¶
Les conventions précédentes concernent uniquement la BDD. Pour les modèles Python, on fera attention à :
Nommer les modèles sans le préfixe « t_ », et à les écrire au singulier. Exemple :
class Observation:.Ne pas répeter le nom des tables dans les noms des colonnes.
Typescript¶
Documenter les fonctions et classes grâce au JSDoc en français (https://jsdoc.app/)
Les commentaires dans le codes doivent être en anglais (ne pas s’empêcher de mettre un commentaire en français sur une partie du code complexe !)
Les messages renvoyés aux utilisateurs sont en français
Installer les outils de devéloppement :
npm install --only=devUtiliser prettier comme formateur de texte et activer l’autoformatage dans son éditeur de texte (VsCode dispose d’une extension Prettier : https://github.com/prettier/prettier-vscode) Pour lancer manuellement prettier depuis le dossier
frontend:
nvm use
npm run format
La longueur maximale pour une ligne de code est 100 caractères.
Angular¶
Suivre les recommandations définies par le styleguide Angular: https://angular.io/guide/styleguide. C’est une ressources très fournie en cas de question sur les pratiques de développement (principe de séparation des principes, organisation des services et des composants)
On privilégiera l’utilisation des reactive forms pour la construction des formulaires (https://angular.io/guide/reactive-forms). Ce sont des formulaires pilotés par le code, ce qui facilite la lisibilité et le contrôle de ceux-ci.
Pour l’ensemble des composants cartographiques et des formulaires (taxonomie, nomenclatures…), il est conseillé d’utiliser les composants présents dans le module “GN2CommonModule”.
HTML¶
La longueur maximale pour une ligne de code est 100 caractères.
Revenir à la ligne avant et après le contenue d’une balise.
Lorsqu’il y a plus d’un attribut sur une balise, revenir à la ligne, aligner les attributs et aller a la ligne pour fermer la balise :
<button
mat-raised-button
color="primary"
class="btn-action hard-shadow uppercase ml-3"
data-toggle="collapse"
data-target="#collapseAvance"
>
Filtrer
</button>
VSCODE fournit un formatteur de HTML par défaut (Dans les options de VsCode, tapez « wrap attributes » et sélectionner « force-expand-multiline »)
En plus du TypeScript/Javascript, Prettier permet de formater le HTML et le SCSS (Se référer à la configuration N’oubliez pas les Typescript.)
Style et ergonomie¶
Boutons : On utilise les boutons d’Angular Material (https://material.angular.io/components/button/overview).
mat-raised-button pour les boutons contenant du texte
mat-fab ou mat-mini-fab pour les boutons d’actions avec seulement une icone
Couleur des boutons :
Action : primary
Validation: vert (n’existant pas dans Material : utiliser la classe button-success)
Suppression: warn
Navigation: basic
Librairie d’icones :
Utiliser la librairie Material icons fournie avec le projet : https://material.io/resources/icons/?style=baseline (
<mat-icon> add </mat-icon>)
Formulaire :
Nous utilisons pour l’instant le style des formulaires Bootstrap (https://getbootstrap.com/docs/4.0/components/forms/). Une reflexion de migration vers les formulaires materials est en cours.
Système de grille et responsive :
Utiliser le système de grille de Bootstrap pour assurer le responsive design sur l’application. On ne vise pas l’utilisation sur mobile, mais à minima sur ordinateur portable de petite taille.
Passer en mode développement¶
Cette section documente comment passer en mode développement une installation de GeoNature initialement faite en mode production.
Récupération des sources¶
Si vous avez téléchargé GeoNature zippé (via la procédure d’installation globale install_all.sh ou en suivant la documentation d’installation standalone), il est nécessaire de rattacher votre répertoire au dépôt GitHub afin de pouvoir télécharger les dernières avancées du coeur en git pull. Pour cela, suivez les commandes suivantes en vous placant à la racine du répertoire de GeoNature.
# Se créer un répertoire .git
mkdir .git
# Récupérer l'historique du dépôt
git clone --depth=2 --bare https://github.com/PnX-SI/GeoNature.git .git
# Initialiser un dépôt git à partir de l'historique téléchargé
git init
# Vérifier que le dépôt distant et le contenu local sont synchronisés
git pull
# Reset sur HEAD pour mettre à jour les status
git reset HEAD
# -> vous êtes à jour sur la branche master
# Cloner les sous-modules pour récupérer les dépendances
git submodule init
git submodule update
Installation du venv en dev¶
Il est nécessaire d’installer les dépendances (sous-modules Git présent dans backend/dependencies) en mode éditable afin de travailler avec la dernière version de celles-ci.
cd backend
source venv/bin/activate
pip install -e .. -r requirements-dev.txt
Configuration des URLs de développement¶
Il est nécessaire de changer la configuration du fichier config/geonature_config.toml pour utiliser les adresses suivantes :
URL_APPLICATION = 'http://127.0.0.1:4200'
API_ENDPOINT = 'http://127.0.0.1:8000'
N’oubliez pas les actions à effectuer après modification de la configuration.
Autres extensions en développement¶
Il n’est pas forcémment utile de passer toutes les extensions en mode dévelomment. Pour plus d’informations, référez-vous aux documentations dédiées :
Développement Backend¶
Démarrage du serveur de dev backend¶
La commande geonature fournit la sous-commande dev-back pour lancer un serveur de test :
source <GEONATURE_DIR>backend/venv/bin/activate
geonature dev-back
L’API est alors accessible à l’adresse http://127.0.0.1:8000.
Arborescence de fichiers¶
Présentation rapide de l’arborescence des fichiers depuis la racine du backend $HOME/geonature/backend
``` /dependencies – sous-modules (Git) des dépendances de GeoNature (UsersHub, Taxhub, RefGeo, etc..) /geonature
- /core – code du coeur de GeoNature, regroupe les différents modèles dont les noms sont proches des schémas de la BDD
/admin – Back office de GeoNature (utilise Flask-admin) /command – Commandes accessibles depuis
geonature */gn_* – Différents modules principaux /imports – Module Import /health – Route permettant vérifier le status de l’instance GeoNature /notifications – Notifications /sensitivity – Gestion de la sensibilité des données /taxonomie – Intégration de Taxhub dans le back office /users – Gestion des utilisateurs/middleware – Custom Flask middleware /migrations – Ensemble des révisions alembic permettant la mise à jour de la BDD de GeoNature /tasks – Tâches asynchrones gérées par Celery /templates – Templates pour surcoucher l’interface d’administration de Flask-Admin /tests – Tests unitaires du backend /utils – Différentes fonctions utilitaires (chargement de la configuration, initialisation de la connexion avec la BDD, etc.) app.py – Création de l”
appflask de GeoNature requirements-*.txt – Liste des dépendances Python de GeoNature Dockerfile – fichier de création de l’image Docker du backend
Base de données avec Flask-SQLAlchemy¶
L’intégration de la base de données à GeoNature repose sur la bibliothèque Flask-SQLAlchemy.
Celle-ci fournit un objet db à importer comme ceci : from geonature.utils.env import db
Cet objet permet d’accéder à la session SQLAlchemy ainsi :
from geonature.utils.env import db
obj = db.session.query(MyModel).get(1)
Mais il fournit une base déclarative db.Model permettant d’interroger encore plus simplement les modèles via leur attribut query :
from geonature.utils.env import db
class MyModel(db.Model):
…
obj = MyModel.query.get(1)
L’attribut query fournit plusieurs fonctions très utiles dont la fonction get_or_404 :
obj = MyModel.query.get_or_404(1)
Ceci est typiquement la première ligne de toutes les routes travaillant sur une instance (route de type get/update/delete).
Fonctions de filtrages¶
L’attribut query est une instance de la classe flask_sqlalchemy.BaseQuery qui peut être surchargée afin de définir de nouvelles fonctions de filtrage.
On pourra ainsi implémenter une fonction pour filtrer les objets auxquels l’utilisateur a accès, ou encore pour implémenter des filtres de recherche.
from flask import g
import sqlalchemy as sa
from flask_sqlalchemy import BaseQuery
from geonature.core.gn_permissions import login_required
class MyModelQuery(BaseQuery):
def filter_by_scope(self, scope):
if scope == 0:
self = self.filter(sa.false())
elif scope in (1, 2):
filters = [ MyModel.owner==g.current_user ]
if scope == 2 and g.current_user.id_organism is not None:
filters.append(MyModel.owner.any(id_organism=g.current_user.id_organism)
self = self.filter(sa.or_(*filters))
return self
class MyModel(db.Model):
query_class = MyModelQuery
@login_required
def list_my_model():
obj_list = MyModel.query.filter_by_scope(2).all()
Sérialisation des modèles avec Marshmallow¶
La bibliothèque Marshmallow fournit des outils de sérialisation et désérialisation.
Elle est intégrée à GeoNature par la bibliothèque Flask-Marshmallow qui fournit l’objet ma à importer comme ceci : from geonature.utils.env import ma.
Cette bibliothèque ajoute notament une méthode jsonify aux schémas.
Les schémas Marshmallow peuvent être facilement créés à partir des modèles SQLAlchemy grâce à la bibliothèque Marshmallow-SQLAlchemy.
from geonature.utils.env import ma
class MyModelSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = MyModel
include_fk = True
Gestion des relationships¶
L’option include_fk=True concerne les champs de type ForeignKey, mais pas les relationships elles-mêmes. Pour ces dernières, il est nécessaire d’ajouter manuellement des champs Nested à notre schéma :
class ParentModelSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = ParentModel
include_fk = True
childs = ma.Nested("ChildModelSchema", many=True)
class ChildModelSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = ChildModel
include_fk = True
parent = ma.Nested(ParentModelSchema)
Attention, la sérialisation d’un objet avec un tel schéma va provoquer une récursion infinie, le schéma parent incluant le schéma enfant, et le schéma enfant incluant le schéma parent. Il est donc nécessaire de restreindre les champs à inclure dans la sérialisation lors de la création du schéma :
- avec l’argument
only: parent_schema = ParentModelSchema(only=['pk', 'childs.pk'])
L’utilisation de
onlya l’inconvénient d’être lourde puisqu’il faut spécifier l’ensemble les champs à sérialiser. De plus, l’ajout d’une nouvelle colonne au modèle nécessite de la rajouter partout où le schéma est utilisé.
- avec l’argument
- avec l’argument
exclude: parent_schema = ParentModelSchema(exclude=['childs.parent'])
Cependant, l’utilisation de
excludeest hautement problématique ! En effet, l’ajout d’un nouveau champsNestedau schéma nécessiterait de le rajouter dans la liste des exclusions partout où le schéma est utilisé (que ça soit pour éviter une récursion infinie, d’alourdir une réponse JSON avec des données inutiles ou pour éviter un problème n+1 - voir section dédiée).
- avec l’argument
La bibliothèque Utils-Flask-SQLAlchemy fournit une classe utilitaire SmartRelationshipsMixin permettant d’exclure par défaut les champs Nested.
Pour demander la sérialisation d’un sous-schéma, il faut le spécifier avec only, mais sans nécessité de spécifier tous les champs basiques (non Nested).
from utils_flask_sqla.schema import SmartRelationshipsMixin
class ParentModelSchema(SmartRelationshipsMixin, ma.SQLAlchemyAutoSchema):
class Meta:
model = ParentModel
include_fk = True
childs = ma.Nested("ChildModelSchema", many=True)
class ChildModelSchema(SmartRelationshipsMixin, ma.SQLAlchemyAutoSchema):
class Meta:
model = ChildModel
include_fk = True
parent = ma.Nested(ParentModelSchema)
Modèles avec nomenclatures¶
Le convertisseur de modèle NomenclaturesConverter permet d’automatiquement ajouter un champs Nested(NomenclatureSchema) pour les relationships vers une nomenclature.
from pypnnomenclature.models import TNomenclatures as Nomenclature
from pypnnomenclature.utils import NomenclaturesConverter
class MyModel(db.Model):
id_nomenclature_foo = db.Column(db.Integer, ForeignKey(Nomenclature.id_nomenclature))
nomenclature_foo = relationship(Nomenclature, foreign_keys=[id_nomenclature_foo])
class MyModelSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = MyModel
include_fk = True
model_converter = NomenclaturesConverter
# automatically added: nomenclature_foo = ma.Nested(NomenclatureSchema)
Le mixin NomenclaturesMixin permet de définir une propriété __nomenclatures__ sur un modèle contenant
la liste des champs à nomenclature.
Cette propriété peut être utilisé pour facilement joindre et inclure lors de la sérialisation les champs à nomenclatures.
from pypnnomenclature.models import TNomenclatures as Nomenclature
from pypnnomenclature.utils import NomenclaturesMixin
class MyModel(NomenclaturesMixin, db.Model):
id_nomenclature_foo = db.Column(db.Integer, ForeignKey(Nomenclature.id_nomenclature))
nomenclature_foo = relationships(Nomenclature, foreign_keys=[id_nomenclature_foo])
# joinedload all nomenclatures
q = MyModel.query.options(*[joinedload(n) for n in MyModel.__nomenclatures__])
# include all nomenclatures to serialization
schema = MyModelSchema(only=MyModel.__nomenclatures__).dump(q.all())
Modèles géographiques¶
En utilisant GeoAlchemyAutoSchema à la place de SQLAlchemyAutoSchema, il est facile de créer des schémas pour des modèles possédant des colonnes géométriques :
Utilisation automatique de
model_converter = GeoModelConverterafin de convertir les colonnes géométriquesExclusion par défaut des colonnes géométriques de la sérialisation
Possibilité de générer du geojson en initialisant le schéma avec
as_geojson=True
Les options suivantes sont disponible (à rajouter comme propriété de la classe Méta, ou comme paramètre à la création du schéma) :
feature_id: Colonne à utiliser pour remplire l’iddes features geojson. Typiquement la clé primaire du modèle. Exclue si non spécifié.feature_geometry: Colonne à utiliser pour définir lageometrydes features geojson. Déterminée automatiquement lorsque le modèle possède une unique colonne géométrique.
class MyModel(db.Model):
pk = db.Column(Integer, primary_key=True)
geom = db.Column(Geometry("GEOMETRY"))
class MyModelSchema(GeoAlchemyAutoSchema):
class Meta:
model = MyModel
feature_id = "pk" # optionnel
feature_geometry = "geom" # automatiquement déterminé
>>> o = MyModel(pk=1, geom=from_shape(Point(6, 10)))
>>> MyModelSchema().dump(o)
{"pk": 1} # la colonne géométrique est automatiquement exclue
>>> MyModelSchema(as_geojson=True).dump(o)
{
"type": "Feature",
"id": 1,
"geometry": {"type": "Point", "coordinates": [6, 10]},
"properties": {"pk": 1}
}
La sortie sera une FeatureCollection lorsque le schéma est utilisé avec many=True.
Les schémas géographiques peuvent également être utilisé pour parser du geojson (Feature ou FeatureCollection).
Modèles géographiques avec nomenclatures¶
Si vous avez un modèle possédant à la fois des relations vers des nomenclatures et des colonnes géométriques,
vous pouvez devoir créer votre propre convertisseur de modèle héritant à la fois de NomenclaturesConverter et de GeoModelConverter :
class NomenclaturesGeoModelConverter(NomenclaturesConverter, GeoModelConverter):
pass
class MyModelSchema(GeoAlchemyAutoSchema):
class Meta:
model = MyModel
model_converter = NomenclaturesGeoModelConverter
Modèles de permission¶
Le mixin CruvedSchemaMixin permet d’ajouter un champs cruved à la sérialisation qui contiendra un dictionnaire avec en clé les actions du cruved et en valeur des booléens indiquant si l’action est disponible.
Pour l’utiliser, il faut :
Définir une propriété
__module_code__(et optionnellement une propriété__object_code__) au niveau du schéma Marshmallow. Ces propriétés sont passées en argument à la fonctionget_scopes_by_action.Le modèle doit définir une fonction
has_instance_permission(scope)prenant en argument une portée (0, 1, 2 ou 3) et renvoyant un booléen.
Par défaut, le CRUVED est exclu de la sérialisation pour des raisons de performance.
Il faut donc demander sa sérialisation lors de la création du schéma avec only=["+cruved"].
Le préfixe + permet de spécifier que l’on souhaite rajouter le cruved aux champs à sérialiser (et non que l’on souhaite sérialiser uniquement le cruved).
from geonature.utils.schema import CruvedSchemaMixin
class MyModel(db.Model):
# …
owner = db.relationship(User)
def has_instance_permission(self, scope):
return scope == 3 or (scope in (1, 2) and self.owner == g.current_user)
class MyModelSchema(CruvedSchemaMixin, ma.SQLAlchemyAutoSchema):
class Meta:
model = MyModel
include_fk = True
__module_code__ = "MODULE_CODE"
# automatically added: cruved = fields.Method("get_cruved", metadata={"exclude": True})
>>> o = MyModel.query.first()
>>> MyModelSchema(only=["+cruved"]).dump(o)
{"pk": 42, "cruved": {"C": False, "R": True, "U": True, "V": False, "E": False}}
Création d’un objet¶
L’utilisation de load_instance=True permet, lors de l’appel de la fonction load, de directement récupérer un objet pouvant être ajouté à la session SQLAlchemy.
class MyModelSchema(SmartRelationshipsMixin, ma.SQLAlchemyAutoSchema):
class Meta:
model = MyModel
include_fk = True
load_instance = True
o = MyModelSchema().load(request.json)
db.session.add(o)
db.session.commit()
Gestion des relationships¶
Many-to-One¶
Exemple d’une relation vers une nomenclature :
class MyModel(db.Model):
id_nomenclature_foo = db.Column(db.Integer, ForeignKey(Nomenclature.id_nomenclature))
nomenclature_foo = relationships(Nomenclature, foreign_keys=[id_nomenclature_foo])
class MyModelSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = MyModel
include_fk = True
model_converter = NomenclaturesConverter
# Le front spécifie directement la ForeignKey et non la relationship :
o = MyModelSchema().load({"id_nomenclature_foo": 42})
Many-to-Many¶
Exemple d’une relation vers plusieurs utilisateurs :
cor_mymodel_user = db.Table(...)
class MyModel(db.Model):
owners = relationship(User, secondary=cor_mymodel_user)
class MyModelSchema(SmartRelationshipsMixin, ma.SQLAlchemyAutoSchema):
class Meta:
model = MyModel
include_fk = True
# Le front spécifie la ForeignKey, la relationship est ignoré :
o = MyModelSchema(only=["owners.id_role"]).load({
"owners": [{"id_role": 42}, {"id_role": 43}]
})
Avertissement
Prendre garde à bien spécifier owners.id_role et non simplement owners, sans quoi il devient possible d’utiliser votre route pour créer des utilisateurs !
One-to-Many¶
Exemple d’une relation vers des modèles enfants rattachés à un unique parent :
class Child(db.Model):
id_parent = db.Column(Integer, ForeignKey(Parent.id))
parent = relationship(Parent, back_populates="childs")
class Parent(db.Model):
id = db.Column(Integer, primary_key=True)
childs = relationship(Child, cascade="all, delete-orphan", back_populates="parent")
class ChildSchema(SmartRelationshipsMixin, ma.SQLAlchemyAutoSchema):
class Meta:
model = MyModel
include_fk = True
load_instance = True
parent = Nested(ParentSchema)
class ParentSchema(SmartRelationshipsMixin, ma.SQLAlchemyAutoSchema):
class Meta:
model = ParentModel
include_fk = True
load_instance = True
childs = Nested(ChildSchema, many=True)
@validates_schema
def validate_childs(self, data, **kwargs):
"""
Ensure this schema is not leveraged to retrieve childs from other parent
"""
for child in data["childs"]:
if child.id_parent is not None and data.get("id") != child.id_parent:
raise ValidationError(
"Child does not belong to this parent.", field_name="childs"
)
o = ParentSchema(only=["childs"], dump_only=["childs.id_parent"]).load({
"pk": 1,
"childs": [
{"pk": 1}, # validate_childs checks child 1 belongs to parent 1
]
})
Avertissement
Prendre garde à ajouter dump_only=["childs.id_parent"], sans quoi il devient possible de créer des objets Child appartenant à un autre Parent !
Avertissement
Prendre garde à ajouter une validation sur le modèle parent de l’appartenance des objets Child, sans quoi il devient possible de rattacher à un parent des objets Child appartenant à un autre parent !
Avertissement
Le frontend doit systématiquement lister l’ensemble des childs, sans quoi ceux-ci seront supprimés.
Serialisation des modèles avec le décorateur @serializable¶
Note
L’utilisation des schémas Marshmallow est probablement plus performante.
La bibliothèque maison Utils-Flask-SQLAlchemy fournit le décorateur @serializable qui ajoute une méthode as_dict sur les modèles décorés :
from utils_flask_sqla.serializers import serializable
@serializable
class MyModel(db.Model):
…
obj = MyModel(…)
obj.as_dict()
La méthode as_dict fournit les arguments fields et exclude permettant de spécifier les champs que l’on souhaite sérialiser.
Par défaut, seules les champs qui ne sont pas des relationshisp sont sérialisées (fonctionnalité similaire à celle fournit par SmartRelationshipsMixin pour Marshmallow).
Les relations que l’on souhaite voir sérialisées doivent être explicitement déclarées via l’argument fields.
L’argument fields supporte la « notation à point » permettant de préciser les champs d’un modèle en relation :
child.as_dict(fields=['parent.pk'])
Les tests unitaires fournissent un ensemble d’exemples d’usage du décorateur.
La fonction as_dict prenait autrefois en argument les paramètres recursif et depth qui sont tous les deux obsolètes. Ces derniers ont différents problèmes :
récursion infinie (contournée par un hack qui ne résoud pas tous les problèmes et qu’il serait souhaitable de voir disparaitre)
augmentation non prévue des données sérialisées lors de l’ajout d’une nouvelle relationship
problème n+1 (voir section dédiée)
Modèles géographiques¶
La bibliothèque maison Utils-Flask-SQLAlchemy-Geo fournit des décorateurs supplémentaires pour la sérialisation des modèles contenant des champs géographiques.
utils_flask_sqla_geo.serializers.geoserializableDécorateur pour les modèles SQLA : Ajoute une méthode as_geofeature qui retourne un dictionnaire serialisable sous forme de Feature geojson.
Fichier définition modèle
from geonature.utils.env import DB from utils_flask_sqla_geo.serializers import geoserializable @geoserializable class MyModel(DB.Model): __tablename__ = 'bla' ...
Fichier utilisation modèle
instance = DB.session.query(MyModel).get(1) result = instance.as_geofeature()
utils_flask_sqla_geo.serializers.shapeserializableDécorateur pour les modèles SQLA :
Ajoute une méthode
as_listqui retourne l’objet sous forme de tableau (utilisé pour créer des shapefiles)Ajoute une méthode de classe
to_shapequi crée des shapefiles à partir des données passées en paramètre
Fichier définition modèle
from geonature.utils.env import DB from utils_flask_sqla_geo.serializers import shapeserializable @shapeserializable class MyModel(DB.Model): __tablename__ = 'bla' ...
Fichier utilisation modèle
# utilisation de as_shape() data = DB.session.query(MyShapeserializableClass).all() MyShapeserializableClass.as_shape( geom_col='geom_4326', srid=4326, data=data, dir_path=str(ROOT_DIR / 'backend/static/shapefiles'), file_name=file_name, )
utils_flask_sqla_geo.utilsgeometry.FionaShapeServiceClasse utilitaire pour créer des shapefiles.
La classe contient 3 méthodes de classe :
FionaShapeService.create_shapes_struct(): crée la structure de 3 shapefiles
(point, ligne, polygone) à partir des colonens et de la geométrie passée en paramètre
FionaShapeService.create_feature(): ajoute un enregistrement
aux shapefiles
FionaShapeService.save_and_zip_shapefiles(): sauvegarde et zip les
shapefiles qui ont au moins un enregistrement
data = DB.session.query(MySQLAModel).all() for d in data: FionaShapeService.create_shapes_struct( db_cols=db_cols, srid=srid, dir_path=dir_path, file_name=file_name, col_mapping=current_app.config['SYNTHESE']['EXPORT_COLUMNS'] ) FionaShapeService.create_feature(row_as_dict, geom) FionaShapeService.save_and_zip_shapefiles()
Réponses¶
Voici quelques conseils sur l’envoi de réponse dans vos routes.
- Privilégier l’envoi du modèle sérialisé (vues de type create/update), ou d’une liste de modèles sérialisés (vues de type list), plutôt que des structures de données non conventionnelles.
def get_foo(pk): foo = Foo.query.get_or_404(pk) return jsonify(foo.as_dict(fields=...)) def get_foo(pk): foo = Foo.query.get_or_404(pk) return FooSchema(only=...).jsonify(foo) def list_foo(): q = Foo.query.filter(...) return jsonify([foo.as_dict(fields=...) for foo in q.all()]) def list_foo(): q = Foo.query.filter(...) return FooSchema(only=...).jsonify(q.all(), many=True)
- Pour les listes vides, ne pas renvoyer le code d’erreur 404 mais une liste vide !
return jsonify([])
Renvoyer une liste et sa longueur dans une structure de données non conventionnelle est strictement inutile, il est très simple d’accéder à la longueur de la liste en javascript via l’attribut
length.Pagination : Flask-SQLAlchemy fournit l’utilitaire db.paginate. Notons qu’il n’est pas nécessaire de récupérer les paramètres
pageetper_pagede la requête puisque cela est fait automatiquement pardb.paginate. Par ailleurs, l’objet Pagination créé pardb.paginatepeut directement être renvoyé passé àjsonifypar votre route ; il sera sérialisé dans une structure commune à l’ensemble de l’application. Ce mécanisme nécessite que le schéma Marshmallow nécessaire à la sérialisation des objets paginés soit indiqué dans la variableg.pagination_schema. Pour cela, vous pouvez utiliser la fonctionpagination_schemaqui crée un contexte et stocke le schéma de sérialisation dans la variableg.pagination_schemaet le supprime après. Sinon, modifiez la variableg.pagination_schemamanuellement. À défaut, GeoNature essayera d’appeler la méthodeas_dict()sur vos objets.- Traitement des erreursutiliser les exceptions prévues à cet effet :
from werkzeug.exceptions import Fobridden, Badrequest, NotFound def restricted_action(pk): if not is_allowed(): raise Forbidden
Penser à utiliser
get_or_404plutôt que de lancer une exceptionNotFoundSi l’utilisateur n’a pas le droit d’effectuer une action, utiliser l’exception
Forbidden(code HTTP 403), et non l’exceptionUnauthorized(code HTTP 401), cette dernière étant réservée aux utilisateurs non authentifiés.- Vérifier la validité des données fournies par l’utilisateur (
request.jsonourequest.args) et lever une exceptionBadRequestsi celles-ci ne sont pas valides (l’utilisateur ne doit pas être en mesure de déclencher une erreur 500 en fournissant une string plutôt qu’un int par exemple !). - Marshmallow peut servir à cela
from marshmallow import Schema, fields, ValidationError def my_route(): class RequestSchema(Schema): value = fields.Float() try: data = RequestSchema().load(request.json) except ValidationError as error: raise BadRequest(error.messages)
- Cela peut être fait avec jsonschema :
from from jsonschema import validate as validate_json, ValidationError def my_route(): request_schema = { "type": "object", "properties": { "value": { "type": "number", }, }, "minProperties": 1, "additionalProperties": False, } try: validate_json(request.json, request_schema) except ValidationError as err: raise BadRequest(err.message)
- Vérifier la validité des données fournies par l’utilisateur (
- Pour les réponses vides (exempleroute de type delete), on pourra utiliser le code de retour 204 :
return '', 204
Lorsque par exemple une action est traitée mais aucun résultat n’est à renvoyer, inutile d’envoyer une réponse « OK ». C’est l’envoi d’une réponse HTTP avec un code égale à 400 ou supérieur qui entrainera le traitement d’une erreur côté frontend, plutôt que de se fonder sur le contenu d’une réponse non normalisée.
Le décorateur @json_resp¶
Historiquement, beaucoup de vues sont décorées avec le décorateur @json_resp.
Celui-ci apparait aujourd’hui superflu en raison de la jsonification automatique par Flask des listes et des dictionnaires. Pour les autres structures de données, Flask fournit l’utilitaire jsonify().
utils_flask_sqla_geo.serializers.json_respDécorateur pour les routes : les données renvoyées par la route sont automatiquement serialisées en json (ou geojson selon la structure des données).
S’insère entre le décorateur de route flask et la signature de fonction
Fichier routes
from flask import Blueprint from utils_flask_sqla.response import json_resp blueprint = Blueprint(__name__) @blueprint.route('/myview') @json_resp def my_view(): return {'result': 'OK'} @blueprint.route('/myerrview') @json_resp def my_err_view(): return {'result': 'Not OK'}, 400
Problème « n+1 »¶
Le problème « n+1 » est un anti-pattern courant des routes de type « liste » (par exemple, récupération de la liste des cadres d’acquisition).
En effet, on souhaite par exemple afficher la liste des cadres d’acquisitions, et pour chacun d’entre eux, la liste des jeux de données :
af_list = AcquisitionFramwork.query.all()
# with Marshmallow (and SmartRelationshipsMixin)
return AcquisitionFrameworkSchema(only=['datasets']).jsonify(af_list, many=True)
# with @serializable
return jsonify([ af.as_dict(fields=['datasets']) for af in af_list])
Ainsi, lors de la sérialisation de chaque AF, on demande à sérialiser l’attribut datasets, qui est une relationships vers la liste des DS associés :
class AcquisitionFramework(db.Model)
datasets = db.relationships(Dataset, uselist=True)
Sans précision, la stratégie de chargement de la relation datasets est select, c’est-à-dire que l’accès à l’attribut datasets d’un AF provoque une nouvelle requête select afin de récupérer la liste des DS concernés.
Ceci est généralement peu grave lorsque l’on manipule un unique objet, mais dans le cas d’une liste d’objet, cela génère 1+n requêtes SQL : une pour récupérer la liste des AF, puis une lors de la sérialisation de chaque AF pour récupérer les DS de ce dernier.
Cela devient alors un problème de performance notable !
Afin de résoudre ce problème, il nous faut joindre les DS à la requête de récupération des AF.
Pour cela, plusieurs solutions :
Le spécifier dans la relationship :
class AcquisitionFramework(db.Model) datasets = db.relationships(Dataset, uselist=True, lazy='joined')
Cependant, cette stratégie s’appliquera (sauf contre-ordre) dans tous les cas, même lorsque les DS ne sont pas nécessaires, alourdissant potentiellement certaines requêtes qui n’en ont pas usage.
- Le spécifier au moment où la requête est effectuée :
from sqlalchemy.orm import joinedload af_list = AcquisitionFramework.query.options(joinedload('datasets')).all()
Il est également possible de joindre les relations d’une relation, par exemple le créateur des jeux de données :
af_list = (
AcquisitionFramework.query
.options(
joinedload('datasets').options(
joinedload('creator'),
),
)
.all()
)
Afin d’être sûr d’avoir joint toutes les relations nécessaires, il est possible d’utiliser la stratégie raise par défaut, ce qui va provoquer le lancement d’une exception lors de l’accès à un attribut non pré-chargé, nous incitant à le joindre également :
from sqlalchemy.orm import raiseload, joinedload
af_list = (
AcquisitionFramework.query
.options(
raiseload('*'),
joinedload('datasets'),
)
.all()
)
Pour toutes les requêtes récupérant une liste d’objet, l’utilisation de la stratégie raise par défaut est grandement encouragée afin de ne pas tomber dans cet anti-pattern.
La méthode as_dict du décorateur @serializable accepte l’argument unloaded='raise' ou unloaded='warn' pour un résultat similaire (ou un simple warning).
L’utilisation de raiseload, appartenant au cœur de SQLAlchemy, reste à privilégier.
Export des données¶
TODO
Utilisation de la configuration¶
La configuration globale de l’application est controlée par le fichier
config/geonature_config.toml qui contient un nombre limité de paramètres.
Il est possible d’utiliser un autre fichier de configuration en spécifiant
un autre chemin d’accès dans la variable d’environnement
GEONATURE_CONFIG_FILE.
Il est également possible de définir des paramètres de configuration par variable
d’environnement en préfixant le nom du paramètre par GEONATURE_ (e.g. GEONATURE_SQLALCHEMY_DATABASE_URI). Cette méthode permet cependant de passer uniquement des valeurs textuelles.
Les paramètres de configuration sont validés par un schéma Marshmallow (voir backend/geonature/utils/config_schema.py).
Dans l’application flask, l’ensemble des paramètres de configuration sont
utilisables via le dictionnaire config :
from geonature.utils.config import config
MY_PARAMETER = config['MY_PARAMETER']
Le dictionnaire config est également accessible via current_app.config.
La configuration des modules est accessible à la clé MODULE_CODE du dictionnaire de configuration. Elle est également accessible directement via la propriété config du blueprint du module :
from flask import current_app
MY_MODULE_PARAMETER = current_app.config['MODULE_CODE']['MY_MODULE_PARAMETER']
MY_MODULE_PARAMETER = blueprint.config['MY_MODULE_PARAMETER']
Authentification et autorisations¶
Accéder à l’utilisateur courant¶
L’utilisateur courant est stocké dans l’espace de nom g :
>>> from flask import g
>>> print(g.current_user)
<User ''admin'' id='3'>
Il s’agit d’une instance de pypnusershub.db.models.User.
Si l’utilisateur n’est pas connecté, g.current_user vaudra None.
Restreindre une route aux utilisateurs connectés¶
Utiliser le décorateur @login_required :
from geonature.core.gn_permissions.decorators import login_required
@login_required
def my_protected_route():
pass
Si l’utilisateur n’est pas authentifié, celui-ci est redirigé vers une page d’authentification, à moins que la requête contienne un header Accept: application/json (requête effectuée par le frontend) auquel cas une erreur 401 (Unauthorized) est levé.
Restreindre une route aux utilisateurs avec un certain scope¶
Utiliser le décorateur @check_cruved_scope :
- @check_cruved_scope¶
- Paramètres:
action (str["C", "R", "U", "V", "E", "D"]) – Type d’action effectuée par la route (Create, Read, Update, Validate, Export, Delete)
module_code (str) – Code du module sur lequel on veut vérifier les permissions.
object_code (str, optional) – Code de l’objet sur lequel on veut vérifier les permissions. Si non fourni, on vérifie la portée sur l’objet
ALL.get_scope (bool, optional) – si
True, ajoute le scope aux kwargs de la vue
Lorsque l’utilisateur n’est pas connecté, le comportement est le même que le décorateur @login_required. Lorsque celui-ci est connecté, le décorateur va récupérer le scope de l’utilisateur pour l’action donnée dans le module donnée (et éventuellement l’objet donnée). Si ce scope est égal à 0, alors une erreur 403 (Forbidden) est levée.
Avertissement
Le décorateur ne vérifie pas si un scope de 1 ou 2 est suffisant pour accéder
aux ressources demandées. C’est à votre route d’implémenter cette vérification,
en utilisant l’argument get_scope=True afin de récupérer la valeur exacte du
scope.
Exemple d’utilisation :
from geonature.core.gn_permissions.decorators import check_cruved_scope
@blueprint.route('/mysensibleview', methods=['GET'])
@check_cruved_scope(
'R',
module_code="OCCTAX"
get_scope=True,
)
def my_sensible_view(scope):
if scope < 2:
raise Forbidden
Récupération manuelle du scope¶
La fonction suivante permet de récupérer manuellement le scope pour un rôle, une action et un module donnés :
- get_scope(action_code, id_role, module_code, object_code)¶
Retourne le scope de l’utilisateur donnée une action dans le module demandé.
- Paramètres:
action_code (str["C", "R", "U", "V", "E", "D"]) – Code de l’action.
id_role (int, optional) – Identifiant du role. Utilisation de
g.current_usersi non spécifié (nécessite de se trouver dans une route authentifiée).module_code (str, optional) – Code du module. Si non spécifié, utilisation de
g.current_moduleobject_code (str, optional) – Code de l’objet. Si non spécifié, utilisation de
g.current_object,ALLà défaut.
- Renvoie:
Valeur du scope
- Type renvoyé:
int[0, 1, 2, 3]
Il est également possible de récupérer les scopes pour l’ensemble des actions possibles grâce à la fonction suivante :
- get_scopes_by_action(id_role, module_code, object_code)¶
Retourne un dictionnaire avec pour clé les actions du CRUVED et pour valeur le scope associé pour un utilisateur et un module donné (et éventuellement un objet précis).
- Paramètres:
id_role (int) – Identifiant du role. Utilisation de
g.current_usersi non spécifié (nécessite de se trouver dans une route authentifiée).module_code (str) – Code du module. Si non spécifié, utilisation de
g.current_modulesi définie,GEONATUREsinon.object_code (str) – Code de l’objet.
ALLsi non précisé.
- Renvoie:
Dictionnaire de scope pour chaque action du CRUVED.
- Type renvoyé:
Exemple d’usage :
>>> from geonature.core.gn_permissions.tools import get_scopes_by_action
>>> get_scopes_by_action(id_role=3, module_code="METADATA")
{'C': 3, 'R': 3, 'U': 3, 'V': 3, 'E': 3, 'D': 3}
Restreindre une route aux utilisateurs avec des permissions avancées¶
Utiliser le décorateur @permissions_required :
- @permissions_required¶
- Paramètres:
action (str["C", "R", "U", "V", "E", "D"]) – Type d’action effectuée par la route (Create, Read, Update, Validate, Export, Delete)
module_code (str) – Code du module sur lequel on veut vérifier les permissions.
object_code (str, optional) – Code de l’objet sur lequel on veut vérifier les permissions. Si non fourni, on vérifie la portée sur l’objet
ALL.
Lorsque l’utilisateur n’est pas connecté, le comportement est le même que le décorateur @login_required.
Lorsque celui-ci est connecté, le décorateur va récupérer l’ensemble des permissions pour l’action donnée dans le module donnée (et éventuellement l’objet donnée).
Si aucune permission n’est trouvée, alors une erreur 403 (Forbidden) est levée.
Avertissement
Le décorateur ne vérifie pas si le jeu de permissions est suffisant pour accéder aux ressources demandées. C’est à votre route d’implémenter cette vérification, celle-ci recevant le jeu de permissions en argument.
Exemple d’utilisation :
from geonature.core.gn_permissions.decorators import permissions_required
@blueprint.route('/mysensibleview', methods=['GET'])
@permissions_required(
'R',
module_code="SYNTHESE"
)
def my_sensible_view(permissions):
for perm in permissions:
if perm.has_other_filters_than("SCOPE", "SENSITIVITY"):
continue
if perm.scope_value > 2 and not perm.sensitivity_filter:
break
else:
raise Forbidden
Récupération manuelle des permissions avancées¶
Utiliser la fonction get_permissions :
- get_permissions(action_code, id_role, module_code, object_code)¶
Retourne l’ensemble des permissions de l’utilisateur donnée pour l’action, le module et l’objet précisé.
- Paramètres:
action_code (str["C", "R", "U", "V", "E", "D"]) – Code de l’action.
id_role (int, optional) – Identifiant du role. Utilisation de
g.current_usersi non spécifié (nécessite de se trouver dans une route authentifiée).module_code (str, optional) – Code du module. Si non spécifié, utilisation de
g.current_moduleobject_code (str, optional) – Code de l’objet. Si non spécifié, utilisation de
g.current_object,ALLà défaut.
- Renvoie:
Liste de permissions
- Type renvoyé:
À propos de l’API « scope »¶
Certains modules supportent des permissions avec plusieurs types de filtres (par exemple, filtre d’appartenance et filtre de sensibilité), ce qui amène à devoir définir plusieurs permissions pour une même action dans un module donnée (par exemple, droit de lecteur des données de mon organisme sans restriction de sensibilité + droit de lecteur des données non sensible sans restriction d’appartenance).
Cependant, cet usage est très peu répandu, la plupart des modules acceptant uniquement un filtre d’appartenance, voir aucun filtre.
Ainsi, l’API « scope » (décorateur @check_cruved_scope, fonctions get_scope et get_scopes_by_action) visent à simplifier l’usage des permissions dans ces modules en résumant les droits de l’utilisateur par un entier de 0 à 4 :
0 : aucune donnée (pas de permission)
1 : données m’appartenant
2 : données appartenant à mon organisme
3 : toutes les données (permission sans filtre d’appartenance)
L’utilisateur héritant des permissions des différents groupes auquel il appartient en plus de ses permissions personnelles, l’API « scope » s’occupe de calculer le scope maximal de l’utilisateur.
Rajouter un nouveau type de filtre¶
On suppose souhaiter l’ajout d’un nouveau type de filtre « foo ».
Rajouter une colonne dans la table
t_permissionsnomméfoo_filterdu type désiré (booléen, entier, …) avec éventuellement une contrainte de clé étrangère. Dans le cas où le filtre peut contenir une liste de valeur contrôlées par une Foreign Key, on préfèrera l’ajout d’une nouvelle table contenant une Foreign Key verst_permissions.id_permission(par exemple, filtre géographique avec liste d’id_areaou filtre taxonomique avec liste decd_nom).Rajouter une colonne booléenne dans la table
t_permissions_availablenomméfoo_filter.Faire évoluer les modèles Python
PermissionetPermissionAvailablepour refléter les changements du schéma de base de données.Compléter
Permission.filters_fieldsetPermissionAvailable.filters_fields(e.g."FOO": foo_filter).Vérifier que la propriété
Permission.filtersfonctionne correctement avec le nouveau filtre : celui-ci doit être renvoyé uniquement s’il est défini. Le cas d’une relationship n’a encore jamais été traité.Optionel : Rajouter une méthode statique
Permission.__FOO_le__(a, b). Celle-ci reçoit en argument 2 filtres FOO et doit renvoyerTruelorsque le filtreaest plus restrictif (au autant) que le filtreb. Par exemple, dans le cas d’un filtre géographique, on renveraTruesibvautNone(pas de restriction géographique) ou si la liste des zonagesaest un sous-ensemble de la liste des zonagesb. Cette méthode permet d’optimiser le jeu de permission en supprimant les permissions redondantes.Compléter la classe
PermFilterqui permet l’affichage des permissions dans Flask-Admin (permissions des utilisateurs et des groupes). Attention, Flask-Admin utilise FontAwesome version 4.Faire évoluer Flask-Admin (classes
PermissionAdminetPermissionAvailableAdmin) pour prendre en charge le nouveau type de filtre.Implémenter le support de son nouveau filtre à l’endroit voulu (typiquement la synthèse).
Compléter ou faire évoluer la table
t_permissions_availablepour déclarer le nouveau filtre comme disponible pour son module.
Développement Frontend¶
Serveur frontend en développement¶
Lancer le serveur frontent en développement :
cd ~/geonature/frontend/
nvm use
npm run start
Le frontend est alors accessible à l’adresse http://127.0.0.1:4200.
Bonnes pratiques¶
Chaque gn_module de GeoNature doit être un module Angular indépendant https://angular.io/guide/ngmodule.
Ce gn_module peut s’appuyer sur une série de composants génériques intégrés dans le module GN2CommonModule et décrit ci-dessous
Les composants génériques¶
Un ensemble de composants décrits ci-dessous sont intégrés dans le coeur de GeoNature et permettent aux développeurs de simplifier la mise en place de formulaires ou de bloc cartographiques.
Voir la DOCUMENTATION COMPLETE sur les composants génériques.
NB : les composants de type « formulaire » (balise input ou select) partagent une logique commune et ont des Inputs et des Outputs communs, décrits ci-dessous. (voir https://github.com/PnX-SI/GeoNature/blob/master/frontend/src/app/GN2CommonModule/form/genericForm.component.ts).
Une documentation complète des composants génériques est disponible ici
NB : les composants de type « formulaire » (balise input ou select) partagent
une logique commune et ont des Inputs et des Outputs communs, décrits
ci-dessous.
(voir https://github.com/PnX-SI/GeoNature/blob/master/frontend/src/app/GN2CommonModule/form/genericForm.component.ts).
Inputs
L’input
parentFormControlde typeFormControl(https://angular.io/api/forms/FormControl) permet de contrôler la logique et les valeurs du formulaire depuis l’extérieur du composant. Cet input est obligatoire pour le fonctionnement du composant.L’input
label(string) permet d’afficher un label au dessus de l’input.L’input
displayAll(boolean, défaut = false) permet d’ajouter un item “tous” sur les inputs de type select (Exemple : pour sélectionner tous les jeux de données de la liste)L’input
multiSelect(boolean, défaut = false) permet de passer les composants de type select en « multiselect » (sélection multiple sur une liste déroulante). Le parentFormControl devient par conséquent un tableauL’input
searchBar(boolean, défaut = false) permet de rajouter une barre de recherche sur les composants multiselectL’input
disabled(boolean) permet de rendre le composant non-saisissableL’input
debounceTimedéfinit une durée en ms après laquelle les évenementsonChangeetonDeletesont déclenchés suite à un changement d’un formulaire. (Par défault à 0)
Outputs
Plusieurs
Outputcommuns à ses composants permettent d’émettre des événements liés aux formulaires.onChange: événement émit à chaque fois qu’un changement est effectué sur le composant. Renvoie la valeur fraiche de l’input.onDelete: événement émit chaque fois que le champ du formulaire est supprimé. Renvoie un évenement vide.
Ces composants peuvent être considérés comme des « dump components » ou « presentation components », puisque que la logique de contrôle est déportée au composant parent qui l’accueille (https://blog.angular-university.io/angular-2-smart-components-vs-presentation-components-whats-the-difference-when-to-use-each-and-why/)
Un ensemble de composants permettant de simplifier l’affichage des cartographies Leaflet sont disponibles. Notamment un composant « map-list » permettant de connecter une carte avec une liste d’objets décrits en détail ci-dessous.
MapListComponent¶
Le composant MapList fournit une carte pouvant être synchronisée
avec une liste. La liste, pouvant être spécifique à chaque module,
elle n’est pas intégrée dans le composant et est laissée à la
responsabilité du développeur. Le service MapListService offre
cependant des fonctions permettant facilement de synchroniser
les deux éléments.
Fonctionnalité et comportement offerts par le composant et le service :
Charger les données
Le service expose la fonction
getData(apiEndPoint, params?)permettant de charger les données pour la carte et la liste. Cette fonction doit être utilisée dans le composant qui utilise le composantMapListComponent. Elle se charge de faire appel à l’API passée en paramètre et de rendre les données disponibles au service.Le deuxième paramètre
paramsest un tableau de paramètre(s) (facultatif). Il permet de filtrer les données sur n’importe quelle propriété du GeoJson, et également de gérer la pagination.Exemple : afficher les 10 premiers relevés du cd_nom 212 :
mapListService.getData('occtax/releve', [{'param': 'limit', 'value': 10'}, {'param': 'cd_nom', 'value': 212'}])
L’API doit nécessairement renvoyer un objet comportant un GeoJson. La structure du l’objet doit être la suivante :
{ "total": "nombre d'élément total", "total_filtered": "nombre d'élément filtré", "page": "numéro de page de la liste", "limit": "limite d'élément renvoyé", "items": "le GeoJson" }
Pour une liste simple sans pagination, seule la propriété “items” est obligatoire.
Rafraîchir les données
La fonction
refreshData(apiEndPoint, method, params?)permet de raffrachir les données en fonction de filtres personnalisés. Les paramètresapiEndPointetparamssont les mêmes que pour la fonctiongetData. Le paramètremethodpermet lui de chosir si on ajoute -append- , ou si on initialise (ou remplace) -set- un filtre.Exemple 1 : Pour filtrer sur l’observateur 1, puis ajouter un filtre sur l’observateur 2 :
mapListService.refreshData('occtax/relevé', 'append, [{'param': 'observers', 'value': 1'}])
puis :
refreshData('occtax/relevé', 'append, [{'param': 'observers', 'value': 2'}])
Exemple 2: pour filtrer sur le cd_nom 212, supprimer ce filtre et filtrer sur le cd_nom 214
mapListService.refreshData('occtax/relevé', 'set, [{'param': 'cd_nom', 'value': 1'}])
puis :
mapListService.refreshData('occtax/relevé', 'set, [{'param': 'cd_nom', 'value': 2'}])
Gestion des évenements :
Au clic sur un marker de la carte, le service
MapListServiceexpose la propriétéselectedRowqui est un tableau contenant l’id du marker sélectionné. Il est ainsi possible de surligner l’élément séléctionné dans le liste.Au clic sur une ligne du tableau, utiliser la fonction
MapListService.onRowSelected(id)(id étant l’id utilisé dans le GeoJson) qui permet de zoomer sur le point séléctionner et de changer la couleur de celui-ci.
Le service contient également deux propriétés publiques geoJsonData (le geojson renvoyé par l’API) et tableData (le tableau de features du Geojson) qui sont respectivement passées à la carte et à la liste. Ces deux propriétés sont utilisables pour interagir (ajouter, supprimer) avec les données de la carte et de la liste.
Selector :
pnx-map-listInputs :
idName:Libellé de l’id du geojson (id_releve, id)
Type:
stringheight:Taille de l’affichage de la carte Leaflet
Type:
string
Exemple d’utilisation avec une liste simple :
<pnx-map-list
idName="id_releve_occtax"
height="80vh">
</pnx-map-list>
<table>
<tr ngFor="let row of mapListService.tableData" [ngClass]=" {'selected': mapListService.selectedRow[0]} == row.id ">
<td (click)="mapListService.onRowSelect(row.id)"> Zoom on map </td>
<td > {{row.observers}} </td>
<td > {{row.date}} </td>
</tr>
</table>
Gestion des erreurs¶
GeoNature utilise un intercepteur générique afin d’afficher un toaster en cas d’erreur lors d’une requête HTTP.
Si vous souhaitez traiter l’erreur vous-même, et empêcher le toaster par défaut de s’afficher, vous pouvez définir un header not-to-handle à votre requête :
this._http.get('/url', { headers: { "not-to-handle": 'true' } })
Tests¶
Pour toute PR ou nouvelle fonctionnalité il est demandé d’écrire des tests. Voir la section dédiée sur l’écriture des tests frontend.
Tests backend¶
Cette documentation a pour objectif d’expliquer comment écrire des tests pour le backend de GeoNature.
Un test se décompose en général en 3 étapes :
Arrange : prépare tous les éléments avant l’exécution de la portion de code à tester (en général une fonction)
Act : exécute cette portion de code
Assert : vérifie que l’exécution s’est bien déroulée
Il est toujours utile de distinguer dans le code ces 3 étapes en ajoutant un commentaire ou une séparation entre elles.
Enfin un test doit être concis, il vaut mieux écrire plusieurs tests pour tester différentes configurations plutôt qu’un seul les testant toutes d’un coup. Cela permet d’identifier plus précisément le test qui n’a pas fonctionné.
Introduction¶
Comme spécifié dans la partie Développement, la librairie Python PyTest est utilisée pour rédiger des tests. Elle permet de :
disposer d’un framework de redaction de tests en se basant notamment sur l’instruction
assertécrire des objets ou des portions de code réutilisables : les
fixtureslancer un même test avec des configurations différentes
faire de nombreuses autres choses décrites dans la documentation PyTest
Utilisation¶
Les tests sont des fonctions pouvant être regroupées dans des classes. La nomenclature est la suivante :
Les tests doivent être situées dans un dossier nommé tests (dans GeoNature, ils sont situés dans
backend/geonature/tests)Le nom de chaque fichier Python contenant des tests doit commencer par
test_Chaque classe comprenant des tests doit commencer par
Test(pas de underscore car la norme PEP8 impose un nom de classe en CamelCase)Chaque nom de test (donc de fonction) doit commencer par
test_pour pouvoir être détecté automatiquement par PyTest
Fixtures¶
Les fixtures de PyTest peuvent permettre de nombreuses choses comme expliqué dans la documentation PyTest sur les fixtures.
Dans GeoNature elles sont, en général, utilisées pour définir des objets réutilisables comme des utilisateurs en base de données pour tester les droits, des observations fictives de taxon pour tester des routes de la synthèse ou encore des éléments non présents en base pour tester que le code voulant les récupérer ne plante pas etc.
Elles sont aussi utilisées pour fournir un contexte à un test. Par exemple, la
fixture temporary_transaction permet de ne pas sauvegarder ce qui sera
inséré/supprimé/modifié dans la base de données pendant le test.
Note
La plupart des fixtures sont rassemblées dans
backend/geonature/tests/fixtures.py, il est important de regarder
lesquelles y sont définies avant d’en écrire d’autres !
Enfin, les fixtures peuvent aussi être définies directement dans le fichier Python du test. Elles sont définies comme suit :
# Obligatoire pour accéder au décorateur
import pytest
# Définit une fixture qui renverra 2
@pytest.fixture()
def my_fixture():
return 2
Et s’utilisent comme suit :
# On passe directement la fixture en argument du test. Il est
# nécessaire de l'importer si elle n'est pas définie dans le même fichier
# Ce test n'est pas dans une classe (donc pas de self)
def test_ma_fonction_a_tester(my_fixture):
result = my_fixture
# On vérifie que la fixture retourne la bonne valeur
assert result == 2
Il est aussi possible de définir un scope d’une fixture comme ceci :
# Définit une fixture qui renverra 2 mais qui sera exécutée qu'une
# seule fois par classe (une classe regroupe plusieurs tests) au
# lieu d'une fois par test. Il est possible aussi de définir ce
# scope au module ou à la function
@pytest.fixture(scope="class")
def my_fixture():
return 2
Exemple¶
Voici un exemple de test qui a été fait dans GeoNature
def test_get_consistancy_data(self):
synthese_record = Synthese.query.first()
response = self.client.get(
url_for("gn_profiles.get_consistancy_data",
id_synthese=synthese_record.id_synthese))
assert response.status_code == 200
Ce test est situé dans une classe (le self est donc obligatoire). Ce test
vérifie que la route gn_profiles.get_consistancy_data fonctionne bien avec
un id_synthese pris dans la base de données. Le assert est directement
interprété par PyTest et le test sera en erreur si la condition n’est pas
respectée. Il est possible d’écrire plusieurs assert pour un même test !
Enfin, une fixture a été utilisée au niveau de la classe pour rendre accessible
l’attribut client de la classe, utile pour faire des requêtes http
notamment.
Dans GitHub¶
Dans le dépôt de GeoNature sur GitHub, tous ces tests sont exécutés automatiquement pour chaque commit d’une pull request grâce à PyTest et à GitHub Actions. Ils permettent donc de vérifier que les modifications apportées par les développeurs ne changent pas le statut des tests et permettent donc aux mainteneurs du projet de disposer d’une meilleure confiance dans la pull request. Un coverage est aussi exécuté pour s’assurer que les nouveaux développements sont bien testés.
Coverage¶
Le coverage est un système permettant de quantifier les lignes de code exécutées par le test. Exemple rapide :
# Définition d'une fonction quelconque
def ma_fonction_a_tester(verbose=False):
if verbose:
return "blablabla"
return "blabla"
# Définition d'un possible test associé
def test_ma_fonction_a_tester():
# Arrange
verbose = True
# Act
message = ma_fonction_a_tester(verbose=verbose)
# Assert
assert message == "blablabla"
Dans cet exemple, un seul test a été écrit où verbose = True donc la
ligne return "blabla" ne sera jamais exécutée par un test. Donc sur les 3
lignes de la fonction, seules 67% des lignes ont été exécutées donc le
coverage serait d’environ (le calcul est plus complexe) 67%. Il faudrait
donc écrire un nouveau test avec verbose = False dans Arrange pour
obtenir 100% de coverage sur la fonction ma_fonction_a_tester().
Avertissement
Un coverage de 100% ne garantit pas un code sans bug ! Il permet plutôt d’être plus confiant dans la modification/refactorisation de lignes de code et dans le développement de nouvelles fonctionnalités.
Dans VSCode¶
Il est possible d’installer l’extension Python pour facilement lancer et
debugger un ou plusieurs tests directement depuis VSCode. Il suffit juste de
changer le fichier settings.json dans le dossier .vscode de votre
projet avec le code suivant pour qu’il soit compatible avec GeoNature :
{
"python.testing.pytestArgs": [
"/chemin/vers/geonature/backend/geonature/tests"
],
"python.testing.unittestEnabled": false,
"python.testing.pytestEnabled": true
}
Pour exécuter les tests de GeoNature placez vous à la racine du dossier où est installé GeoNature et exécutez la commande suivante :
pytest
Assurez vous d’avoir bien installé les librairies de développement avant (en étant toujours placé à la racine de l’installation de GeoNature) :
pip install -e .[tests]
Pour exécuter un seul test l’option -k est très utile :
pytest -k 'test_uuid_report_with_dataset_id'
Ici, elle exécutera uniquement le test test_uuid_report_with_dataset_id (du
ficher test_gn_meta.py).
Enfin, pour générer le coverage en même temps que les tests :
pytest --cov --cov-report xml
Le format xml est interprété par l’extension VSCode Coverage Gutters qui fournie directement dans le code les lignes couvertes et celles non parcourues par le test.
Si vous souhaitez voir le coverage directement depuis le navigateur, il est
possible de générer le coverage au format html en remplaçant xml par
html.
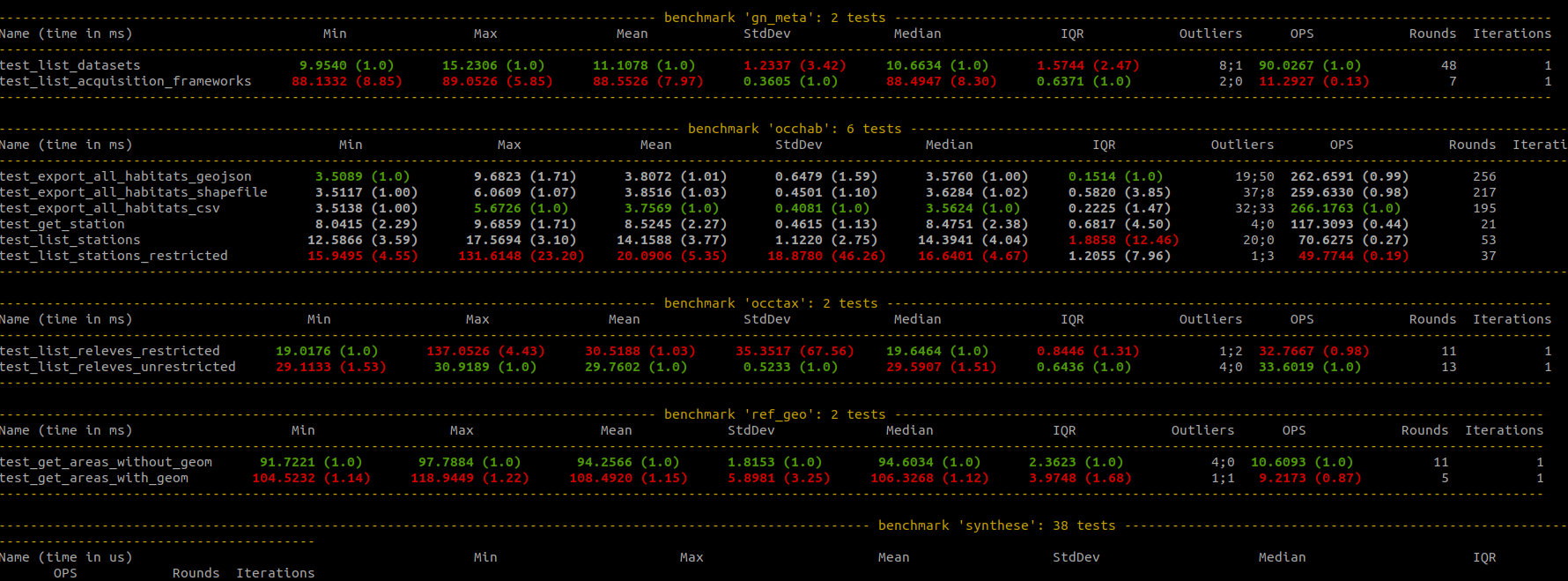
Evaluer les performances du backend¶
Les versions de GeoNature >2.14.1 intègrent la possibilité d’évaluer les performances de routes connues pour leur temps de traitement important. Par exemple, l’appel de la route gn_synthese.get_observations_for_web avec une géographie non-présente dans le référentiel géographique.
Cette fonctionnalité s’appuie sur pytest et son extension ``pytest-benchmark``(https://pytest-benchmark.readthedocs.io/en/latest/).
Pour lancer les tests de performances, utiliser la commande suivante : pytest --benchmark-only
La création de tests de performance s’effectue à l’aide de la classe geonature.tests.benchmarks.benchmark_generator.BenchmarkTest.
L’objet BenchmarkTest prend en argument :
La fonction dont on souhaite mesurer la performance
Le nom du test
Les
argsde la fonctionles
kwargsde la fonction
Cette classe permet de générer une fonction de test utilisable dans le _framework_ existant de pytest. Pour cela, rien de plus simple ! Créer un fichier de test (de préférence dans le sous-dossier backend/geonature/tests/benchmarks).
Import la classe BenchmarkTest dans le fichier de test.
import pytest
from geonature.tests.benchmarks import BenchmarkTest
Ajouter un test de performance, ici le test test_print qui teste la fonction print de Python.
bench = BenchmarkTest(print,"test_print",["Hello","World"],{})
Ajouter la fonction générée dans bench dans une classe de test:
@pytest.mark.benchmark(group="occhab") # Pas obligatoire mais permet de compartimenter les tests de performances
@pytest.mark.usefixtures("client_class", "temporary_transaction")
class TestBenchie:
test_print = bench()
Note
Le décorateur @pytest.mark.benchmark permet de configurer l’éxecution des tests de performances par pytest-benchmark. Dans l’exemple ci-dessus, on l’utilise pour regrouper les tests de performances
déclarés dans la classe TestBenchie dans un groupe nommée occhab.
Si le test de performances doit accéder à des fonctions ou des variables uniquement accessibles dans le contexte
de l’application flask, il faudra utiliser l’objet geonature.tests.benchmarks.CLater. Ce dernier permet
de déclarer un expression python retournant un objet (fonction ou variable) dans une chaîne de caractère qui
sera _évalué_ (voir la fonction eval() de Python) uniquement lors de l’exécution du benchmark.
test_get_default_nomenclatures = BenchmarkTest(
CLater("self.client.get"),
[CLater("""url_for("gn_synthese.getDefaultsNomenclatures")""")],
dict(user_profile="self_user"),
)()
L’exécution de certaines benchmark de routes doivent inclure l’engistrement d’utilisateur de tests. Pour cela,
il suffit d’utiliser la clé user_profile dans l’argument kwargs (Voir code ci-dessus).
Si l’utilisation de _fixtures_ est nécessaire à votre test de performance, utilisé la clé fixture
dans l’argument kwargs:
test_get_station = BenchmarkTest(
CLater("self.client.get"),
[CLater("""url_for("occhab.get_station", id_station=8)""")],
dict(user_profile="user", fixtures=[stations]),
)()
Tests frontend¶
Cette documentation a pour objectif d’expliquer comment écrire des tests pour le frontend de GeoNature.
L’écriture de tests frontend dans GeoNature se base sur l’outil Cypress dont il est nécessaire de maitriser et comprendre le fonctionnement.
Pré-requis¶
Le lancement des tests Cypress nécessite la présence de données en base : la branche Alembic cypress-samples-test doit être upgraded.
Il faut également utiliser le contenu du fichier config/test_config.toml.
Rédaction¶
Principe de base : un test doit être concis. Il vaut mieux écrire plusieurs tests pour tester différentes configurations plutôt qu’un seul les testant toutes d’un coup. Cela permet d’identifier plus précisément le test qui n’a pas fonctionné.
La rédaction des fichiers de tests se fait dans le dossier frontend/cypress/e2e.
Structure¶
La nomenclature des fichiers de test est XXXXXXX-spec.js (XXXX correspondant au nom du module testé).
Afin d’améliorer la lisibilité des fichiers de test si un module contient beaucoup de tests il est nécessaire de séparer les tests end to end en plusieurs fichiers et les placer dans un dossier portant le nom du module.
Exemple¶
e2e
├── import
│ ├── all-steps-spec.js
│ └── list-search-spec.js
Dans chaque fichier la structure des tests est de la forme
- une description
test
test
…
Exemple¶
describe("description général de la partie testée", () => {
it('description du test 1', () => {
//contenu du test 1
})
it('description du test 2', () => {
//contenu du test 2
})
})
Afin d’homogénéiser les descriptions des tests il est établi que l’on nomme un test en anglais en commençant par should.
Exemple¶
it('should change the state',() => ...
Implémentation¶
La réalisation des tests frontend passe par la sélection des objets HTML du DOM. A fin de rendre ces sélections plus propres, on peut ajouter des tags HTML dans le dom. Angular et Cypress suggèrent l’ajout de tags de ce type:
data-qa
test-qa
data-test
Il est recommandé d’utiliser un nom explicite pour éviter toutes confusions.
Exemple¶
<button data-qa="import-list-new">New</button>
Voir https://docs.cypress.io/guides/references/best-practices#Selecting-Elements pour les bonnes pratique de sélection d’éléments.
Lancement¶
Pour lancer Cypress et executer les tests à la main il faut exécuter la commande (nécessite qu’une instance GeoNature fonctionne (backend+frontend)):
npm run cypress:open
Pour lancer les test en mode automatique, il faut exécuter la commande (utilisée dans l’intégration continue (GitHub Action)):
npm run e2e:ci && npm run e2e:coverage
Développer un module externe¶
GeoNature a été conçu pour fonctionner en briques modulaires.
Chaque protocole, répondant à une question scientifique, est amené à avoir son propre module GeoNature comportant son modèle de base de données (dans un schéma séparé), son API et son interface utilisateur.
Les modules développés s’appuieront sur le coeur de GeoNature qui est constitué d’un ensemble de briques réutilisables.
En base de données, le coeur de GeoNature est constitué de l’ensemble des
référentiels (utilisateurs, taxonomique, nomenclatures géographique)
et du schéma gn_synthese regroupant l’ensemble données saisies dans les
différents protocoles (voir doc administrateur pour plus de détail sur le
modèle de données).
L’API du coeur permet d’interroger les schémas de la base de données « coeur » de GeoNature. Une documentation complète de l’API est disponible dans la rubrique API.
Du côté interface utilisateur, GeoNature met à disposition un ensemble de composants Angular réutilisables pour l’affichage des cartes, des formulaires etc…
Avant de développer un gn_module, assurez-vous d’avoir GeoNature bien installé sur votre machine (voir Installation de GeoNature uniquement).
Afin de pouvoir connecter ce module au « coeur », il est impératif de suivre une arborescence prédéfinie par l’équipe GeoNature. Un template GitHub a été prévu à cet effet (https://github.com/PnX-SI/gn_module_template). Il est possible de créer un nouveau dépôt GitHub à partir de ce template, ou alors de copier/coller le contenu du dépôt dans un nouveau.
Cette arborescence implique de développer le module dans les technologies du coeur de GeoNature à savoir :
Le backend est développé en Python grâce au framework Flask.
Le frontend est développé grâce au framework Angular (voir la version actuelle du coeur)
GeoNature prévoit cependant l’intégration de module « externe » dont le frontend serait développé dans d’autres technologies. La gestion de l’intégration du module est à la charge du développeur.
Le module se placera dans un dossier à part du dossier « GeoNature » et portera le suffixe « gn_module ». Exemple : gn_module_validation
Le backend doit être un paquet Python. Ce paquet peut définir différent entry points permettant de renseigner différentes informations sur votre module :
code: le MODULE_CODE de votre module (obligatoire)picto: le pictogramme par défaut pour l’entrée dans le menu Geonature (facultatif)blueprint: le blueprint qui sera servit par GeoNature (obligatoire)config_schema: un schéma Marshmallow permettant de valider la configuration du module (obligatoire)migrations: l’emplacement de vos migrations Alembic pour le schéma de base de données de votre module (facultatif)alembic_branch: le nom de la branche Alembic (par défaut, la branche Alembic devra porter le nom du module code en minuscule)tasks: votre fichier de tâches asynchrones Celery (facultatif)
Le frontend doit être placé dans un sous-dossier
frontend. Il comprendra les éléments suivants :Les fichiers
package.jsonetpackage-lock.jsonavec vos dépendances (facultatif si pas de dépendances)Un dossier
assetsavec un sous-dossier du nom du module avec l’ensemble des médias (images, son)Un dossier
appqui comprendra le code de votre module, avec notamment le « module Angular racine » qui doit impérativement s’appelergnModule.module.ts
Pour l’installation du module, voir Installation d’un module GeoNature.
Bonnes pratiques Frontend¶
Pour l’ensemble des composants cartographiques et des formulaires (taxonomie, nomenclatures…), il est conseillé d’utiliser les composants présents dans le module “GN2CommonModule”.
Importez ce module dans le module racine de la manière suivante
import { GN2CommonModule } from '@geonature_common/GN2Common.module';
Les librairies JS seront installées dans le dossier
node_modulesde GeoNature. (Il n’est pas nécessaire de réinstaller toutes les librairies déjà présentes dans GeoNature (Angular, Leaflet, ChartJS …). Lepackage.jsonde GeoNature liste l’ensemble des librairies déjà installées et réutilisable dans le module.Les fichiers d’assets sont à ranger dans le dossier
assetsdu frontend. Angular-cli impose cependant que tous les assets soient dans le répertoire mère de l’application (celui de GeoNature). Un lien symbolique est créé à l’installation du module pour faire entre le dossier d’assets du module et celui de Geonature.Utiliser node_modules présent dans GeoNature
Pour utiliser des librairies déjà installées dans GeoNature, utilisez la syntaxe suivante
import { TreeModule } from "@librairies/angular-tree-component";
L’alias
@librairiespointe en effet vers le repertoire des node_modules de GeoNaturePour les utiliser à l’interieur du module, utiliser la syntaxe suivante
<img src="assets/<MY_MODULE_CODE>/afb.png">
Exemple pour le module de validation
<img src="assets/<gn_module_validation>/afb.png">
Intégrer l’import de données dans votre module¶
A partir de la version 2.15, le module d’Import permet l’ajout de nouvelles destinations en plus de la Synthèse. Cela a été l’occasion d’ajouter la possibilité d’importer des données d’habitat dans le module Occhab. Cette section présente le processus d’ajout de l’import dans votre module GeoNature.
Modification à apporter sur la base de données¶
Plusieurs points sont essentiels au bon fonctionnement de l’import dans votre module :
Avoir une permission C sur votre module de destination
Créer un objet destination (bib_destinations) et autant d’entités (bib_entities) que vous avez d’objets dans votre module (e.g. habitat, station pour Occhab)
Créer une table transitoire permettant d’effectuer la complétion et le contrôle des données avant l’import des données vers la table de destination finale.
Pour chaque entité, déclarer les attributs rendus accessibles à l’import dans bib_fields
Si de nouvelles erreurs de contrôle de données doivent être déclarées, ajouter ces dernières dans bib_errors_type
N.B. Comme dans le reste de GeoNature, il est conseillé d’effectuer les modifications de base de données à l’aide de migrations Alembic.
Permissions requises¶
Si ce n’est pas le déjà cas, ajouter la permission de création de données dans votre module. Le code ci-dessous donne un exemple fonctionnant dans une révision alembic.
op.execute(
"""
INSERT INTO
gn_permissions.t_permissions_available (id_module,id_object,id_action,label,scope_filter)
SELECT
m.id_module,o.id_object,a.id_action,v.label,v.scope_filter
FROM
(
VALUES
('[votreModuleCode', 'ALL', 'C', True, 'Créer [nomEntité]')
) AS v (module_code, object_code, action_code, scope_filter, label)
JOIN
gn_commons.t_modules m ON m.module_code = v.module_code
JOIN
gn_permissions.t_objects o ON o.code_object = v.object_code
JOIN
gn_permissions.bib_actions a ON a.code_action = v.action_code
"""
)
Créer votre destination et vos entités¶
Dans un premier temps, il faut créer une « destination ». Pour cela, il faut enregistrer votre module dans bib_destinations.
# Récupérer l'identifiant de votre module
id_de_votre_module = (
op.get_bind()
.execute("SELECT id_module FROM gn_commons.t_modules WHERE module_code = 'CODE_DE_VOTRE_MODULE'")
.scalar()
)
# Ajouter la destination
# N.B. table_name correspond au nom de la future table transitoire
destination = Table("bib_destinations", meta, autoload=True, schema="gn_imports")
op.get_bind()
.execute(
sa.insert(destination)
.values(
id_module=id_de_votre_module,
code="votre_module_code",
label="VotreModule",
table_name="t_imports_votre_module",
)
)
Dans votre module, plusieurs objets sont manipulés et stockés chacun dans une table. Pour prendre l’exemple du module Occhab, on a deux entités les stations et les habitats.
id_dest_module= (
op.get_bind()
.execute("SELECT id_destination FROM gn_imports.bib_destinations WHERE code = 'votre_module_code'")
.scalar()
)
entity = Table("bib_entities", meta, autoload=True, schema="gn_imports")
op.get_bind()
.execute(
sa.insert(entity)
.values(
id_destination=id_dest_module,
code="code_entite1",
label="Entite1",
order=1,
validity_column="entite1_valid",
destination_table_schema="votre_module_schema",
destination_table_name="entite1_table_name",
)
)
Créer votre table transitoire¶
Nécessaire pour le contrôle de données, il est important de créer une table transitoire permettant d’effectuer la complétion et le contrôle des données avant l’import des données vers la table de destination finale. La table transitoire doit contenir les colonnes suivantes :
id_import : identifiant de l’import
line_no : entier, numéro de la ligne dans le fichier source
entityname_valid : booleen, indique si une entité est valide
pour chaque champ de l’entité, il faudra une colonne VARCHAR contenant la donnée du fichier et une colonne du type du champ qui contiendra la données finales. La convention de nommage est la suivante: « src_nomchamp » pour colonne contenant la données du fichier source et « nomchamp » pour la colonne contenant les données finales. Il est conseillé que le nom de la colonne contenant les données finales soit identiques à celle du champs dans la table de destination.
op.create_table(
"t_imports_votremodule",
sa.Column(
"id_import",
sa.Integer,
sa.ForeignKey("gn_imports.t_imports.id_import", onupdate="CASCADE", ondelete="CASCADE"),
primary_key=True,
),
sa.Column("line_no", sa.Integer, primary_key=True),
sa.Column("entite1_valid", sa.Boolean, nullable=True, server_default=sa.false()),
# Station fields
sa.Column("src_id_entite", sa.Integer),
sa.Column("id_entite", sa.String),
sa.Column("src_unique_dataset_id", sa.String),
sa.Column("unique_dataset_id", UUID(as_uuid=True)),
[...]
)
Déclarer les attributs rendus accessibles à l’import dans bib_fields¶
Pour chaque entité (e.g. une station dans Occhab), il faut déclarer les champs du modèles accessibles à l’import dans bib_fields.
theme = Table("bib_themes", meta, autoload=True, schema="gn_imports")
id_theme_general = (
op.get_bind()
.execute(sa.select([theme.c.id_theme]).where(theme.c.name_theme == "general_info"))
.scalar()
)
fields_entities=[
(
{
"name_field": "id_entite1",
"fr_label": "Identifiant entité1",
"mandatory": True, # Obligatoire ou non
"autogenerated": False, # généré automatique (ex. UUID)
"display": False, # Afficher dans l'UI
"mnemonique": None,
"source_field": None,
"dest_field": "id_entite1",
},
{
id_entity1: { # récupérer l'id de l'entité entité1 précédement inséré
"id_theme": id_theme_general,
"order_field": 0,
"comment": "", # Utilisé comme tooltip
},
},
),
...
]
field = Table("bib_fields", meta, autoload=True, schema="gn_imports")
id_fields = [
id_field
for id_field, in op.get_bind()
.execute(
sa.insert(field)
.values([{"id_destination": id_votre_dest, **field} for field, _ in fields_entities])
.returning(field.c.id_field)
)
.fetchall()
]
cor_entity_field = Table("cor_entity_field", meta, autoload=True, schema="gn_imports")
op.execute(
sa.insert(cor_entity_field).values(
[
{"id_entity": id_entity, "id_field": id_field, **props}
for id_field, field_entities in zip(id_fields, fields_entities)
for id_entity, props in field_entities[1].items()
]
)
)
Ajout de nouvelles erreurs de contrôle de données¶
Il est possible que votre module nécessite de déclarer de nouveaux contrôles de données. Ces contrôles peuvent provoquer de nouvelles erreurs que celle déclaré dans bib_errors_type. Il est possible d’en ajouter comme dans l’exemple suivant :
error_type = sa.Table("bib_errors_types", metadata, schema="gn_imports", autoload_with=op.get_bind())
op.bulk_insert(
error_type,
[
{
"error_type": "Erreur de format booléen",
"name": "INVALID_BOOL",
"description": "Le champ doit être renseigné avec une valeur binaire (0 ou 1, true ou false).",
"error_level": "ERROR",
},
{
"error_type": "Données incohérentes d'une ou plusieurs entités",
"name": "INCOHERENT_DATA",
"description": "Les données indiquées pour une ou plusieurs entités sont incohérentes sur différentes lignes.",
"error_level": "ERROR",
},
...
],
)
Configuration¶
Il faut d’abord créer une classe héritant de la classe ImportActions
class VotreModuleImportActions(ImportActions):
def statistics_labels() -> typing.List[ImportStatisticsLabels]:
# Retourne un objet contenant les labels pour les statistiques
@staticmethod
def process_fields(destination, fields):
# Effectue un traitement sur les données des champs d'imports (Voir table bib_fields)
# Utilisé dans le cas de monitoring pour remplacer les variables de configurations
# de monitoring (e.g. __MODULE.ID_LIST_TAXONOMY) dans les paramètres de champs.
@staticmethod
def preprocess_transient_data(imprt: TImports, df) -> None:
# Effectue un pré-traitement des données dans un dataframe
@staticmethod
def check_transient_data(task, logger, imprt: TImports) -> None:
# Effectue la validation des données
@staticmethod
def import_data_to_destination(imprt: TImports) -> None:
# Importe les données dans la table de destination
@staticmethod
def remove_data_from_destination(imprt: TImports) -> None:
# Supprime les données de la table de destination
@staticmethod
def report_plot(imprt: TImports) -> StandaloneEmbedJson:
# Retourne des graphiques sur l'import
@staticmethod
def compute_bounding_box(imprt: TImports) -> None:
# Calcule la bounding box
Dans cette classe on retrouve toutes les fonctions obligatoires, à implementer pour pouvoir implementer l’import dans un module.
Méthodes à implémenter¶
statistics_labels()
Fonction qui renvoie un objet de la forme suivante :
{"key": "station_count", "value": "Nombre de stations importées"},
{"key": "habitat_count", "value": "Nombre d’habitats importés"},
Les statistiques sont calculées en amont, et ajoutés à l’objet import dans la section statistique. Les valeurs des clés permettent de définir les labels à afficher pour les statistique affichées dans la liste d’imports.
preprocess_transient_data(imprt: TImports, df)
Fonction qui permet de faire un pré-traitement sur les données de l’import, elle retourne un dataframe panda.
check_transient_data(task, logger, imprt: TImports)
Dans cette fonction est effectuée la validation et le traitement des données de l’import.
La fonction check_dates, par exemple, utilisée dans l’import Occhab permet de valider tous les champs de type date présents dans l’import.
Elle vérifie que le format est respecté.
La fonction check_transient_data permet de génerer les uuid manquants dans l’import, elle permet notamment de générer un UUID commun à différentes lignes de l’import quand id_origin est le même.
import_data_to_destination(imprt: TImports)
Cette fonction permet d’implémenter l’import des données valides dans la table de destination une fois que toutes les vérifications ont été effectuées.
remove_data_from_destination(imprt: TImports)
Cette fonction permet de supprimer les données d’un import, lors de la suppression d’un import.
C’est notamment pour pouvoir implémenter cette fonction que la colonne id_import est préconisée dans les tables de destination.
report_plot(imprt: TImports)
Cette fonction permet de créer les graphiques affichés dans le raport d’import. Pour créer ces graphiques on utilise la librairie bokeh (documentation : https://docs.bokeh.org/en/latest/). Il y a des exemples de création de graphiques dans l’import Occhab.
compute_bounding_box(imprt: TImports)
Cette fonction sert à calculer la bounding box des données importées, c’est-à-dire le plus petit polygone dans lequel sont contenues toutes les données géographique importées. Cette bounding box est affichée dans le rapport d’import une fois toutes les données validées.
Documentation¶
La documentation se trouve dans le dossier docs.
Elle est écrites en ReStructuredText et généré avec Sphinx.
Pour générer la documentation HTML :
Se placer dans le dossier
docs:cd docsCréer un virtualenv :
python3 -m venv venvActiver le virtualenv :
source venv/bin/activateInstaller les dépendances nécessaires à la génération de la documentation :
pip install -r requirements.txtLancer la génération de la documentation :
make html
La documentation générée se trouve dans le dossier build/html/.
Release¶
Pour sortir une nouvelle version de GeoNature :
Faites les éventuelles Releases des dépendances (UsersHub, TaxHub, UsersHub-authentification-module, Nomenclature-api-module, RefGeo, Utils-Flask-SQLAlchemy, Utils-Flask-SQLAlchemy-Geo)
Assurez-vous que les sous-modules git de GeoNature pointent sur les bonnes versions des dépendances et que le
requirements-dependencies.ina bien été mis à jour.Regénérer les fichiers
requirements.txtetrequirements-dev.txtavec les commandes suivantes dans la plus petite version de python supportée par GeoNaturepip-compile requirements.in > requirements.txt pip-compile requirements-dev.in > requirements-dev.txt
Mettez à jour la version de GeoNature et éventuellement des dépendances dans
install/install_all/install_all.iniComplétez le fichier
docs/CHANGELOG.md(en comparant les branches https://github.com/PnX-SI/GeoNature/compare/develop) et dater la version à sortirMettez à jour le fichier
VERSIONMergez la branche
developdans la branchemasterFaites la release (https://github.com/PnX-SI/GeoNature/releases) en la taguant
X.Y.Z(sansvdevant) et en copiant le contenu du ChangelogDans la branche
develop, modifiez le fichierVERSIONenX.Y.Z.dev0et pareil dans le fichierdocs/CHANGELOG.mdFaites la release de GeoNature-Docker-services avec la nouvelle version de GeoNature, et éventuellement des modules (Voir un exemple)
Faites la release sur GeoNature_db avec la nouvelle version de GeoNature et des modules externes